 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximating Context-Free Grammars with a Finite-State Calculus
Nov 11, 1997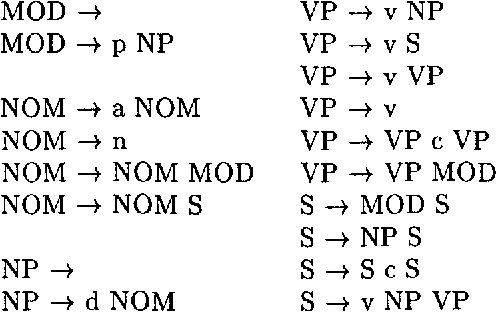
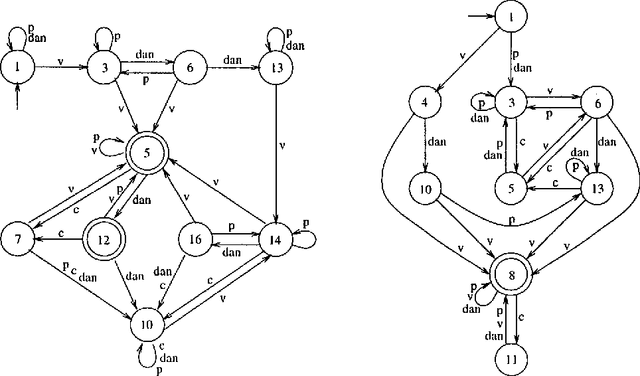
Although adequate models of human language for syntactic analysis and semantic interpretation are of at least context-free complexity, for applications such as speech processing in which speed is important finite-state models are often preferred. These requirements may be reconciled by using the more complex grammar to automatically derive a finite-state approximation which can then be used as a filter to guide speech recognition or to reject many hypotheses at an early stage of processing. A method is presented here for calculating such finite-state approximations from context-free grammars. It is essentially different from the algorithm introduced by Pereira and Wright (1991; 1996), is faster in some cases, and has the advantage of being open-ended and adaptable.
* 8 pages, LaTeX, 2 PostScript figures, aclap.sty
Compiling a Partition-Based Two-Level Formalism
May 02, 1996This paper describes an algorithm for the compilation of a two (or more) level orthographic or phonological rule notation into finite state transducers. The notation is an alternative to the standard one deriving from Koskenniemi's work: it is believed to have some practical descriptive advantages, and is quite widely used, but has a different interpretation. Efficient interpreters exist for the notation, but until now it has not been clear how to compile to equivalent automata in a transparent way. The present paper shows how to do this, using some of the conceptual tools provided by Kaplan and Kay's regular relations calculus.